[AI in] Scientific discovery
From Deepmind to graph reasoning and beyond
![[AI in] Scientific discovery](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1741197393152%2F97e89b0e-eb4c-4dc2-9be9-56ced7c5efe3.png&w=3840&q=75)

Literally me
One thing - I’ll add own thoughts on where each area is moving (science/ventures) so we’ll be able to point fingers and laugh later!
Deepmind’s co-scientist
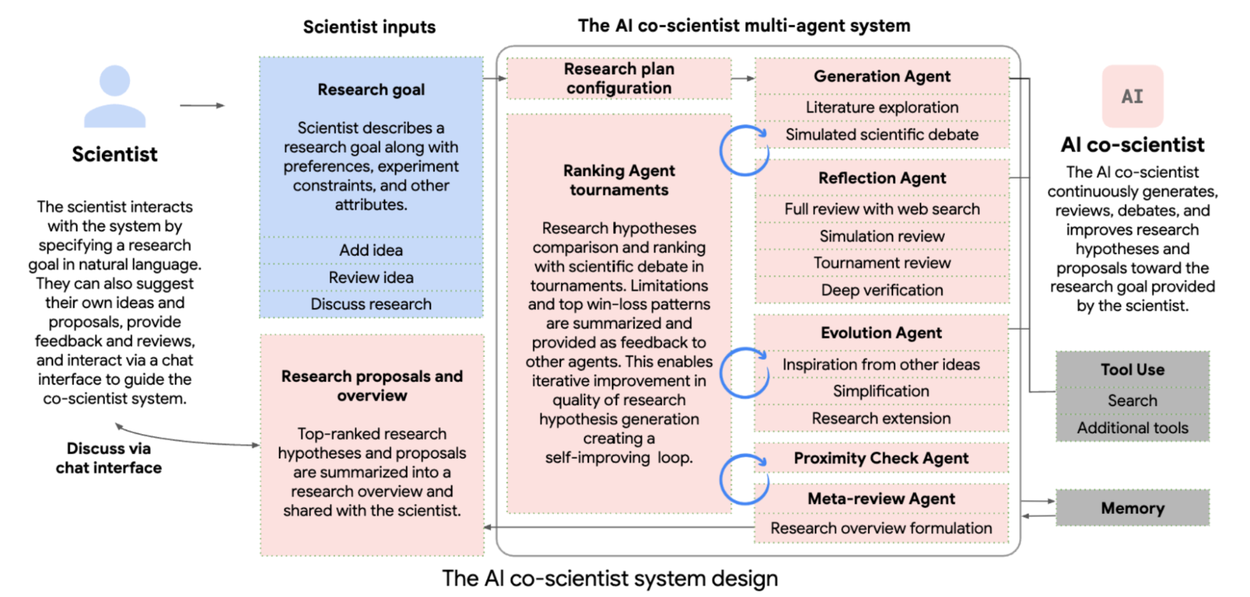
So, after Alphafold (protein folding prediction, one of the ‘unsolvable scientific mysteries’) and GNoME (discovering 2M+ materials, 300K+ of which are indeed worthy of future research), Deepmind has released an agentic system for scientific discovery. Contrary to the multitude of LLM-generated bullcrap that had predictably infested publishing houses, and even Stanford’s STORM (source code) that generates hypotheses and debates them.
Any results?
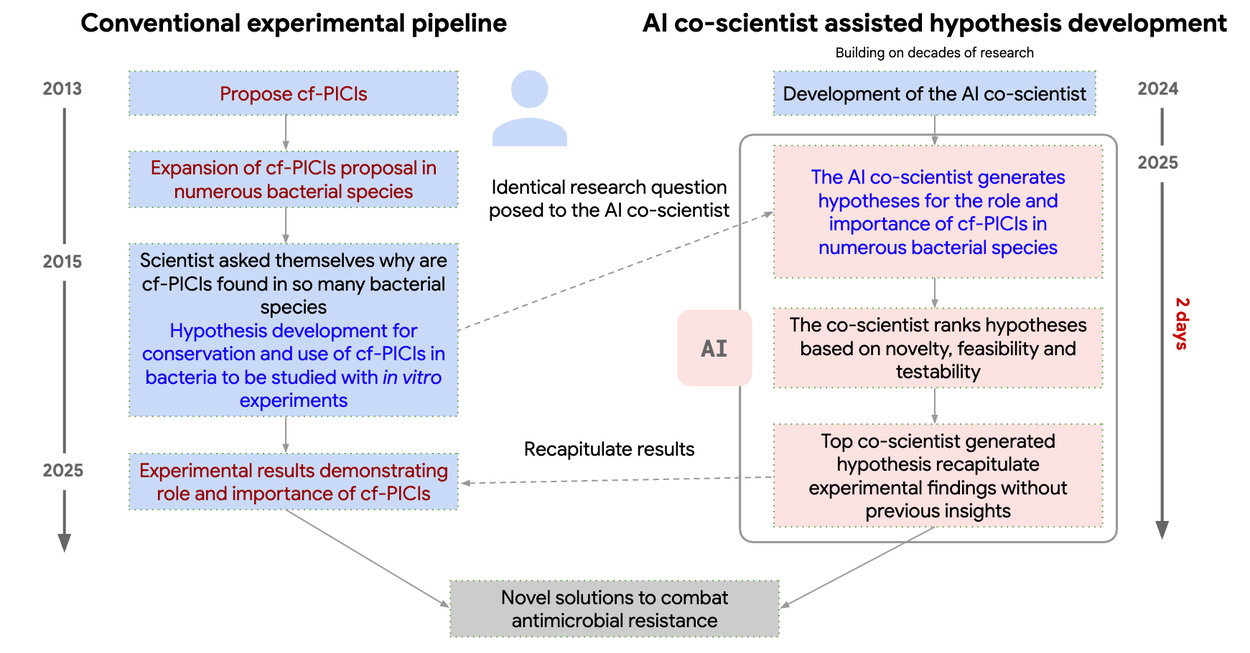
One of the fascinating cherry-picked examples is packing ~10 years of antimicrobial resistance research into 2 days of agent inference. The solutions were comparable or better than current SotA research on antimicrobial resistance.
Co-scientist is able to use Internet, but currently seems unable to automatically simulate/check the hypotheses. Still, this proves as an incredibly powerful tool - Deepmind’s at it again ❣️
Further developments (🧂)
Meaning “take this with a grain of salt”
Loosely based on this comment of mine:
Heuristic/metric automated ideation and development
Checking the hypotheses where possible, using the required tools (e.g. an exposed API to an affinity checker, etc.)
Generating the critic-generator-judge (later meta-judge, e.g. meta-rewarding LLMs) sub-agent structure
No, please noAuto-publishing after human verificationNo, no, no, noAuto-reviewing other papers, e.g. LLMs-as-scientific-reviewers
And products on each and every stage.
Anyway, given the recent rise of LLMs-as-judges and other “let’s take this 0.5-12B param and finetune so it…” cases, we could IMO expect further productization of different LLM-based specialization areas. The old “do one thing and do it really well” adage applies here without any friction.
Graphs for scientific discovery
Launching in 3…2…1…Pew-pew-pew!
Recently I’ve stumbled upon awesome work by Prof. Marcus Buehler from MIT. Starting with fine-tuned models for materials science to more complex graph-based reasoning first. Being interested in graphs and neurosymbolic approaches (covered before), I’ve started diving like a ravenous whale.

LLM approach was checked out first…
So:
a graph was created from 1000+ papers
calculating node metrics
devising optimal graph reasoning algorithms and techniques
a lot of weird similarities were found between materials’ properties graphs and, e.g., Beethoven’s 9th Symphony

using graph reasoning and principles from Kandinsky’s ‘Composition VII’ painting (that was weird, okay) to generate materials, incl. using DALL-E

Graph attention next!
Next frontier I loved was replacing the usual Transformer attention module with Graph Isomorphic Networks (paper, source code)

TLDR (explanation here, too)
the usual attention is Q, K, V - Query, Key, Value; nicely explained by e.g. Ebrahim Pichka, or an awesome (!) visualization by Brendan Bycroft, and another one. Multi-head latent attention as the ‘trendiest’ below:
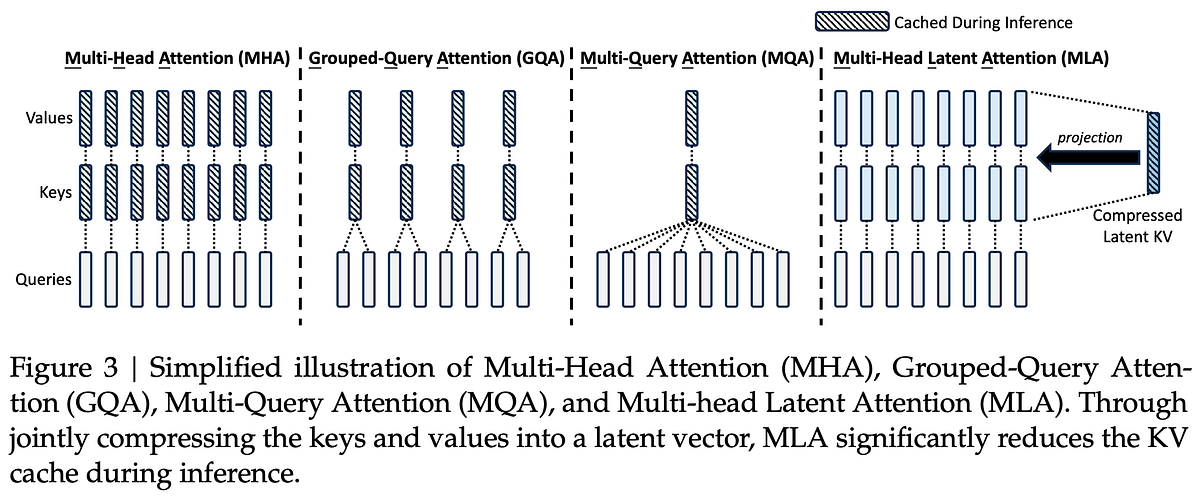
it’s replaced by an graph isomorphism (to tell the truth, it’s not the only lab that pursues GTs) network-like structure (i.e. are the graphs of the same shape, and what is the difference)

each token is viewed as a node, attention score is edge weight
adjacency matrix (graph representation) is computed, and aggregated to calculate the output
for multi-head attention, each head computes an individual GIN adjacency matrix which are then concatenated
GIN introduces a sharpening parameter α (⬆️ α leads to sharper attention, while ⬇️ α produces a smoother distribution) to dynamically shift ‘attention focus’
sparse graphs are used for greater expressivity and lower computational overhead
(e.g. why put up a 0.000(…) weight why you can optimize)
Later on, it still seems like a multi-agent scientific reasoner (SciAgents), but using graphs as a world model:
We trained a graph-native reasoning AI, then let it think for days & discovered that it formed a dynamic relational world model on its own, no pre-programming. Emergent hubs, small-world properties, modularity, & scale-free structures arose naturally. The model then exploited compositional reasoning & uncovered uncoded properties from deep synthesis: Materials with memory, microbial repair, self-evolving systems.

Recent paper + breakdown

It outlines how the last version of the sci-discovery system works:
Question or topic for pondering (“Does Shrek think of Roman Empire?”)
Thinking in <thinking></thinking> tags a-la DeepSeek et al., but more akin to knowledge graph
Extracting new knowledge (i.e. local subgraphs to integrate into ‘world model’ graph, e.g. “wood + fire = coal + ash” → ADD {“wood IS material”, “wood COMBINES with fire”})
Merging with big global graph
Next prompt
Repeat → (1)
And there’s also a simple generator-critic style agent loop that incorporates graph enrichers/generators, too:

In the end…we’re getting a system that has an interpretable and explainable world model:

Yet I may be mistaken and propose that there should be a world graph consensus/verification mechanism or agent somewhere! An idea for a pet project… Another one…
Other approaches, e.g. JEPA
I’ve written about Yann LeCun’s JEPA architecture before. This approach seems to move forward, with causal understanding of, for example, physics laws:

As soon as I’ve pondered on combining JEPA learning with graph representations - someone’s already published a paper on it.

A graph representation is learned; but those are not knowledge graphs at the moment. Another thing - nothing enriches the graph using logic laws.
![Knowledge Graph Reasoning Made Simple [3 Technical Methods]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2024/02/query2vec.jpg?fit=1200%2C675&ssl=1)
Other things that caught my attention
Tokenized architecture - IMO any kind of parametric encoding/hot-swapping is the step in the right direction
Google Titans as a new memory paradigm (surprise-based, usage-retaining, dynamically reorganizing → all the features of real memory)
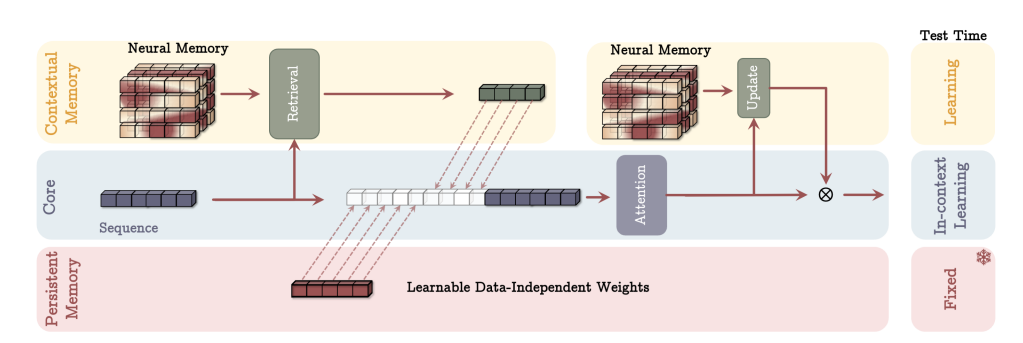
A generalized world model graph, or maybe specialized ones? WikiData seems OK for the start. Or Google’s.

Definitely some bio-inspired computing, or bio-computing altogether. Cortical Labs, I’m looking at you! How long until this computer learns to play DoTa…
Other emerging computing paradigms that may (!) lift off are:
reversible computing (i.e. internally recycling the heat/energy generated by calculations), spearheaded by Vaire. A pretty awesome write-up here

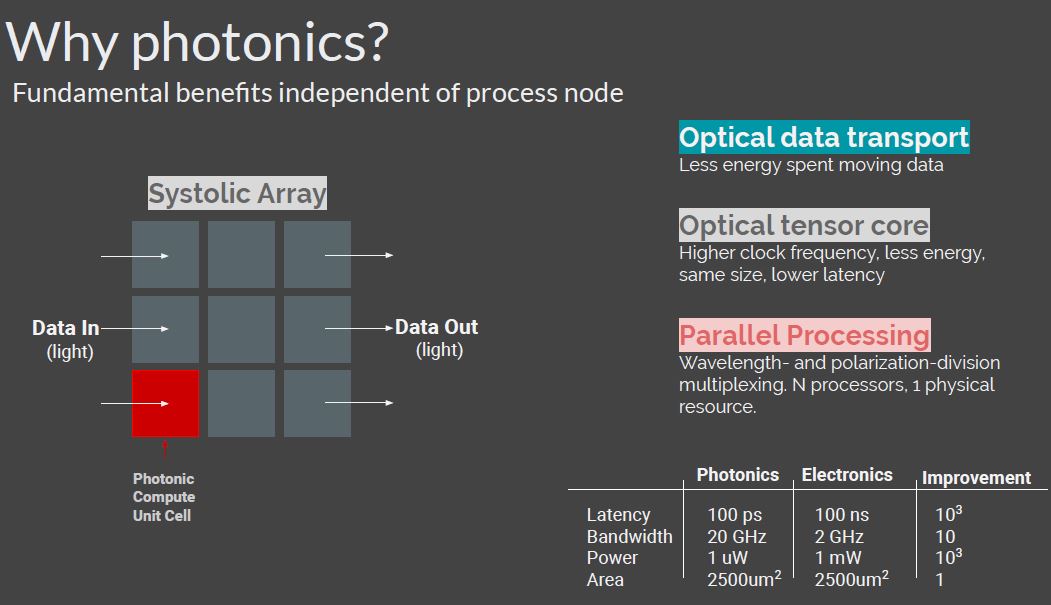
photonic chips and Lightmatter + recent MIT advances (“was able to complete the key computations for a machine-learning classification task in less than half a nanosecond while achieving more than 92 percent accuracy*”*). It’s a chip that uses photons instead of electrons for several improvements:
the long-hyped quantum computing (explanation here → uses quantum phenomena to process information faster, e.g. quantum entanglement to calculate several states at once), where lots are battling - starting with MS with their recent Majorana release, to e.g. Rigetti with a 9-qubit (at the moment) chip, D-Wave and Quantum Computing
The landscape is pretty, pretty dense even with a 2-yr old chart:

Future directions (🧂)
Productized → on-premises → commodified “specific scientific discovery AIs” for one’s own purposes (i.e. one hooks it up to own simulation/heuristic systems to check hypotheses, working in collaboration with scientists, or at some point alone).
Market: CAGR at a whopping 53.7%
Possible strategy: backing companies leveraging the advances / backing the ‘boring’ enablers (APIs/products/security, etc.)
Goal/architecture-encoded “scientific AI” akin to TART, so it’s more generalized and adaptable
Fast-faster chips (one of the paradigms will blow up for sure), and IMO more specialized chips (e.g. programmable-encodable FPGAs for the particular task at hand, it seems) akin to Lisp machines of the past.
The market is so big it’s indecent to mention - at least 1T by 2030 (will actually be bigger if we consider the emerging chip paradigm race)
Possible strategy - backing several early-to-mid stage paradigms
Infrastructure/enablers, i.e. storage, data transfer, orchestration, energy storage and production, automation… You name it.
Welcome to Teleogenic❣️
Other places I cross-post (not always) to: