With some of the points Mr. LeСun rises in his recent paper on generative AI and a proposed architecture called JEPA (Joint Embedding and Prediction Architecture, sounds especially good in Russian).
Let's try to uncover the main points!
ML and HL

Hygh life is not a novelty. Okay, that's actually human learning in comparison to machine learning. Mr. LeCun's quotes are in italics.
Machine learning virgin
Supervised learning (SL)
Requires large numbers of labeled samples.
Reinforcement learning (RL)
Requires insane amounts of trials.
Self-Supervised Learning (SSL)
Requires large numbers of unlabeled samples.
SSL by LeCun

Human learning Chad

In comparison, human and (not every) animal learning is much more efficient:
Causality
Understanding how the world works;
Can predict the consequences of their actions;
Reasoning and planning
Can perform chains of reasoning with an unlimited number of steps;
Can plan complex tasks by decomposing it into sequences of subtasks.
Auto-regressive LLMs are
likely not the solution. It's a black box approach with correct answer probability of
$$P(correct) = (1-e)^n$$
This diverges exponentially. Of course, there are some projects tackling that - but IMO some kind of a stopper, as with plain generative AI, is needed.
Think of it as a negative feedback mechanism, an autoreceptor:

So, in short words, there are a lot of things going potentially wrong - basically, exponential bullshit risks on any level of effects.
New kids on the block
Modular autonomous AI architecture

Basically, a bayesian predicting regret-minimizing machine. Yeah, it resembles the things Anil Seth mentioned in his "Being You" and paper.
Yeah, our brains may really be Bayesian prediction machines as per free energy minimization principle.
And yeah, regret ~= prediction error here: it's abs(expectation - reality).
P.S. Andrew Gallimore's "Reality Switch Technologies" provides roughly the same account: prediction errors flow upwards the cognitive hierarchy, and only mismatch signals are used to update the model (as this delta is what can help minimize the prediction error).
It consists of:
Configurator
Basic configuration and update module.
Perception
The "sensory" part that receives signals.
World model
One of the main modules: it predicts the future world state.
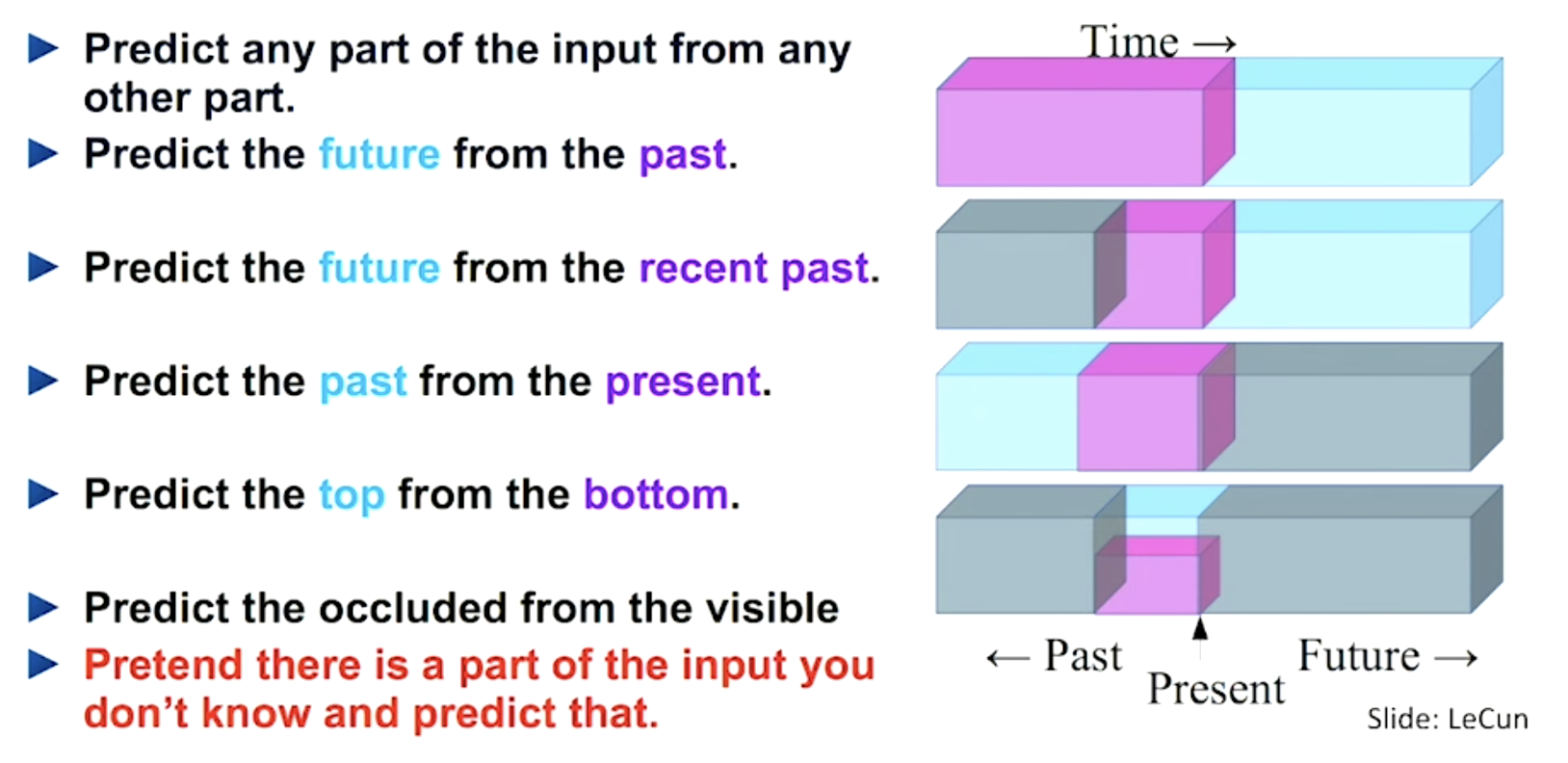
For that, it should account for world being not fully predictable - a bane of generative models in part causing hallucinations. Yeah, yeah, contextual and chain prompting, lots of practical steps, yada yada yada - still, those are band aids.

Welcome to JEPA

It predicts only an abstract representation of future state, y
It actively looks for minimizing the "energy" by giving higher scoring/priority to incompatible present -> future pairs (x -> y)

EBMs
A mega-short primer on Energy-based models, quoting Wiki: EBMs capture dependencies by associating an unnormalized probability scalar (energy) to each configuration of the combination of observed and latent variables. Inference consists of finding (values of) latent variables that minimize the energy given a set of (values of) the observed variables.
Scalar: almost a vector, but not:
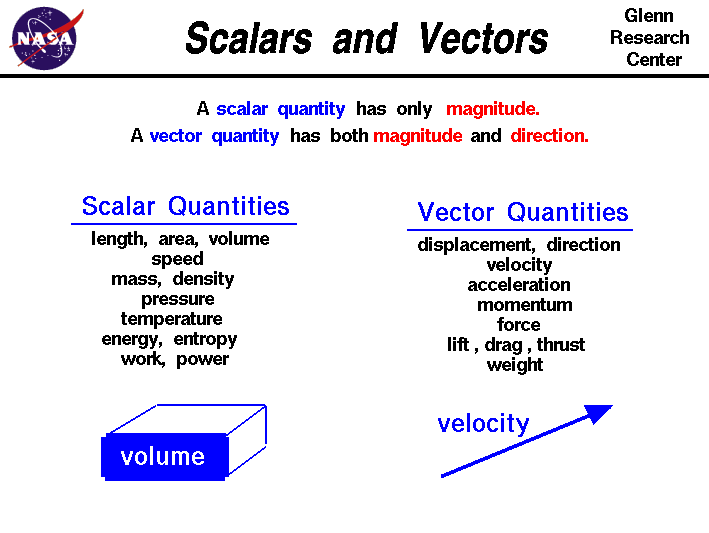
Unnormalized means the scalars can have a sum of >1, despite what we're used to with probability - a probability space can damn well have it at 146%!
So, in simpler words:
we have some variants of future y, each with a probability of it happening;
we're looking for the value of y that is the most probable -> coursing to the next reality node that everything is converging to. As Wiki says, this is an advantage: An EBM can generate sharp, diverse samples or (more quickly) coarse, less diverse samples. Given infinite time, this procedure produces true samples.
It's Apple's patent net, but still looking like a solid ohmygod-complex-graph I was looking for...
Critic/cost module
Assesses and tries to minimize:
information content of z, latent configurator variable/vector
the "cost" of traversing to next prediction state, i.e. prediction error (may be wrong here)
While maximizing the information content of present and future states (akin to Integrative Information Theory's maximality measure)

Actor
It acts, huh.
Short-term memory
Stores state-cost pairs/"episodes".
Abstractness
Again, YL notes that low-level representations (up to the last detail) are mostly suitable for short-term predictions. A good example of this is a weather forecast - when trying to predict the next state down to the degree/number of rain drops, we're destined to suffer from a higher prediction error (and soaked documents, yeah).
In contrast, higher-level/more abstract (ermmm we're moving towards future, yeah, definitely) are more "robust" so to say.
Hierarchical planning
Now the important things
An action at level k specifies an objective for level k-1 ->so we're using actions arising from abstract predictions to set lower-level goals. Sounds obvious yet reasonable;
Prediction in higher levels are more abstract and longer-range.
Final
YL proposes
Abandon generative models in favor joint-embedding architectures
Abandon Auto-Regressive generation
Abandon probabilistic model in favor of energy-based models
Abandon contrastive methods in favor of regularized methods
Abandon Reinforcement Learning in favor of model-predictive control
Use RL only when planning doesn't yield the predicted outcome, to adjust the world model or the critic.
YL defines the following steps
towards Autonomous AI systems:
Self-Supervised Learning (Almost everything is learned through self-supervised learning, and almost nothing - through reinforcement, supervision or imitation)
To learn representations of the world
To learn predictive models of the world (Prediction is the essence of intelligence + common sense)
Handling uncertainty in predictions
Learning world models from observation, like animals and humans: Human learning Chad. Also, emotions/regret/prediction error is quite important: anticipation of outcomes by the critic or world model+intrinsic cost.
Reasoning and planning: Hierarchical planning
Reasoning == simulation/prediction + optimization of objectives (Reasoning and planning)
That is compatible with gradient-based learning
No symbols, no logic → vectors & continuous functions
Final words?
Probabilistic generative models and contrastive methods are doomed.

Welcome to Teleogenic/YAWN/Boi Diaries❣️
You can find the other blogs I try to cross-post to: