Brandolini's AI, and an unexpected virtue of a research proposal
Worm AI, incentive modelling
Bullshit AImetry principle

As we've discussed before, Brandolini's law states that generating unverified information is an order of magnitude easier than refuting it. It seems to climax with generative AI: erroneous facts can cost billions, as in the late case of Google's Bard advertisement, or just the calculation errors as in Zillow's case with overvalued home buying.
In short, checking a model's output requires:
Knowing the area - you can’t check a proposed microservice architecture if you’re not an architect;
Spending the resources/energy to check;
Being critical - spotting a possible error and re-checking it without the halo effect applicable to the AI (it’s a kind of magic, magic, MAGIC)

This brings us to, in my opinion, a problem that arises:
How do we know the truth?
We don't need to know the absolute truth, obviously - it’s individual, in the eye of the beholder, yada yada. But we need to distinguish the factual truth from ‘opinionated’ truth, may I say so. Let’s visit Wikipedia as Stanford doesn’t have the consensus theory.
So, I propose to have a look at correspondence, coherence, pragmatic and consensus theories and look at them in a kind of a spectrum (as always, yeah). Yeah, verifying the truth itself, ‘cause why not.

Truthing the truth
For us to be OK with the results of, say, a newborn god-AGI, they’ve got to be:
In accordance with the facts and first principles as per correspondence theory
You don’t want a flat earth made of gorgonzola.
(Usually) fitting into the current systems of beliefs/truths as per coherence theory
I.e. there is a place for contrarian thinking, and discoveries, but not when you’re asking for particular dates or, say, code.
Usable and useful in practical terms as per the pragmatic theory
Otherwise, what’s the point in truth if it doesn’t help progress, get happier, eliminate suffering, generate porn fanfics, and revert entropy after all?
Agreed upon by the feedback as per consensus theory
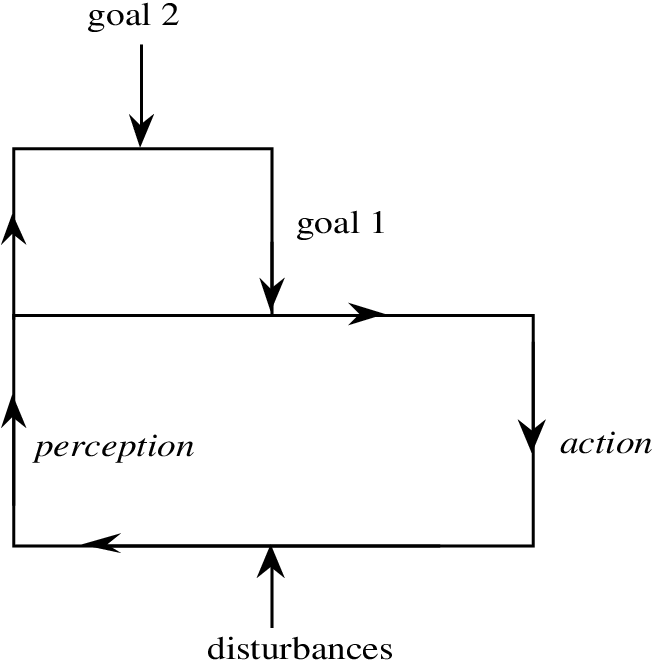
It’s a frontier that can be both a blessing and a curse - a potential attack vector for the AI and the community. But agents’ and/or environment agreement and feedback can be crucial. A kind of self-supervised consensus from the unfolding future’s feedback can be modelled, IMO, from the OODA loop. Modified, of course:
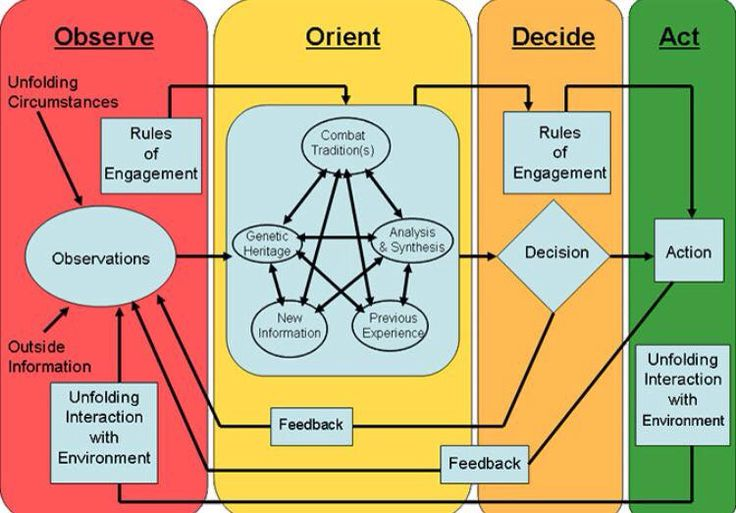
Another assumption - this all can’t be 100%. We can only be so much confident in something and have a probability of being correct. So, it’s all going a way of kinda-bayesian updating:

How do we model an AI to account for (not only) that?
I’m sure superminds are working on that right now, but let’s imagine I’m sitting in a box (okay, barrel) and speaking with myself:

Another thing to account for is unfolding circumstances and uncertainty. As we’ve moved from VUCA to BANI, incomprehensible complexity, and non-linearity are ruling with ambiguousness still in place.
Agents that operate successfully (I won’t delve further here) should:
find optimal strategies to operate under, again, uncertainty and risk: basically, maximize the expected value of actions. It resembles Sharpe Ratio, but in life:
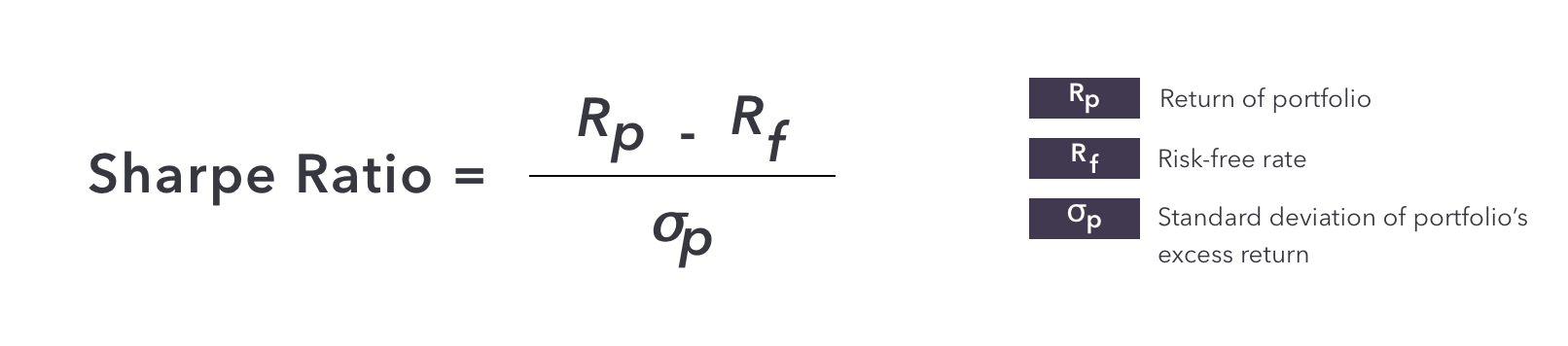
be teleogenic: teleogenesis is, in simple terms, self-setting goals. An even simpler example: you’re buying PB&J to make a sandwich:
teleogenesis presumes adaptability: an adaptable system can change its behaviour (and itself) in response to feedback/conditions;
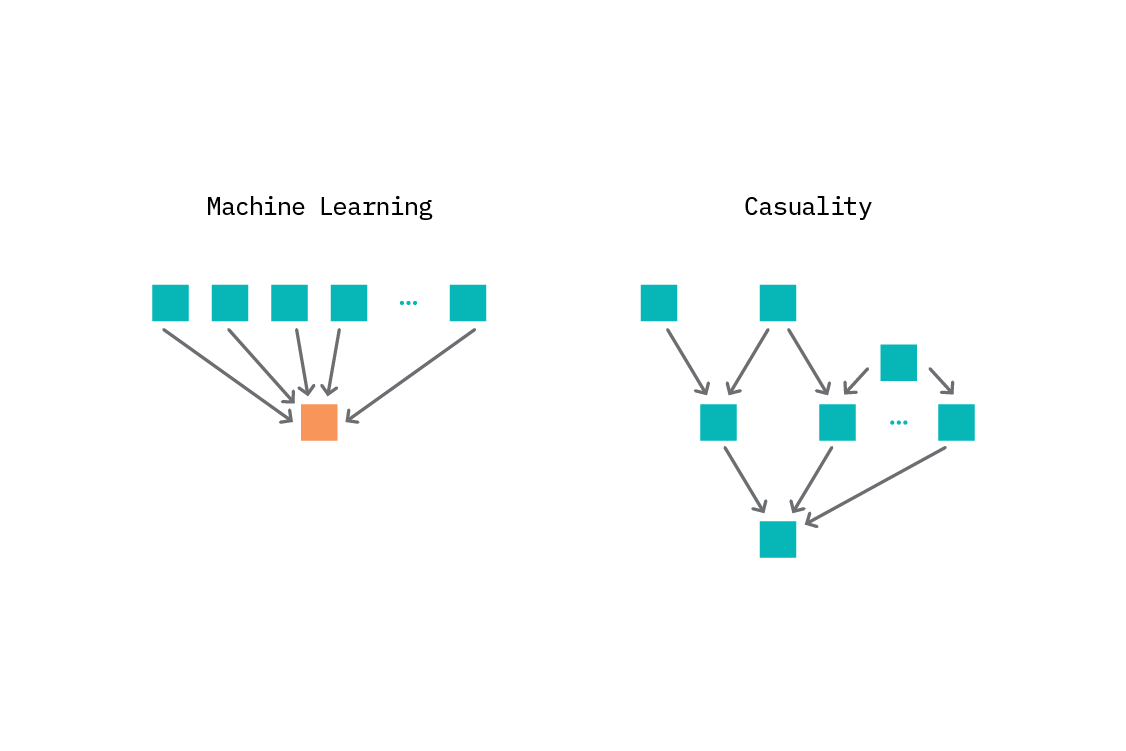
understand, and not just generate. We’ve come closer to understanding what distinguishes us from an AI at the moment, and it’s changing the neural representation in time - changing the network itself as it learns more. One of the approaches to start capturing that is, IMO, causal learning - “capturing the causal mechanism based on the observed data, a new set of variables and assumptions, and incorporate the changes in data distribution when subject to different interventions”
understanding, closer to first principles the better, helps bring insights and actions that are closer to factual, coherent and pragmatic truth
For an artificial intelligence system, and I’m talking more integrative stuff, that means being able to:
self-tune, in the case of ML - that starts with the AutoAI concept and, not the least, reward functions. A faulty and/or inflexible reward function can cause a lot of problems, so we need to learn doing it
draw causal relationships and infer from that (please take a look at chapters on (3) The great lie of ML, Dangers of spurious correlations, and (6) Causal graphs)
prune and change its structure akin to evolution and neutrality theory, as well as synaptic pruning

in the end comes teleogenesis: not just choosing the best model, but setting a task to choose the best model, i.e. understanding how to get to some goal. Here, I presume, we’ll come to an AI alignment and ethic problem - and this may well be the stepping stone most researchers wouldn’t want or just won’t tread onto. However - if you don’t do something, someone else will, as a bedrock maxim, stands true here IMO
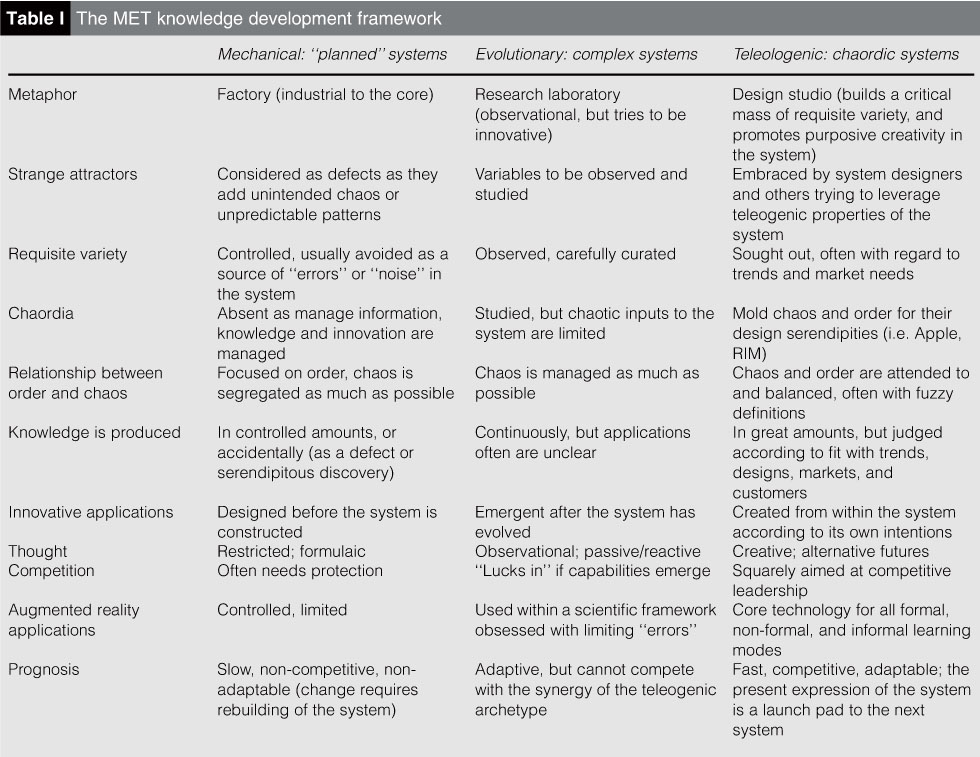
Quantitative limits and qualitative changes
One more crucial thing is resource intensiveness. Evolutionary/simulating algorithms may eventually take a forbiddingly high toll on resources, requiring more and more to (FEED ME) be trained and used for inference. There are some approaches, such as (getting billions of funding ahem cough) using decentralized computation.
Luckily, some other approaches exist.
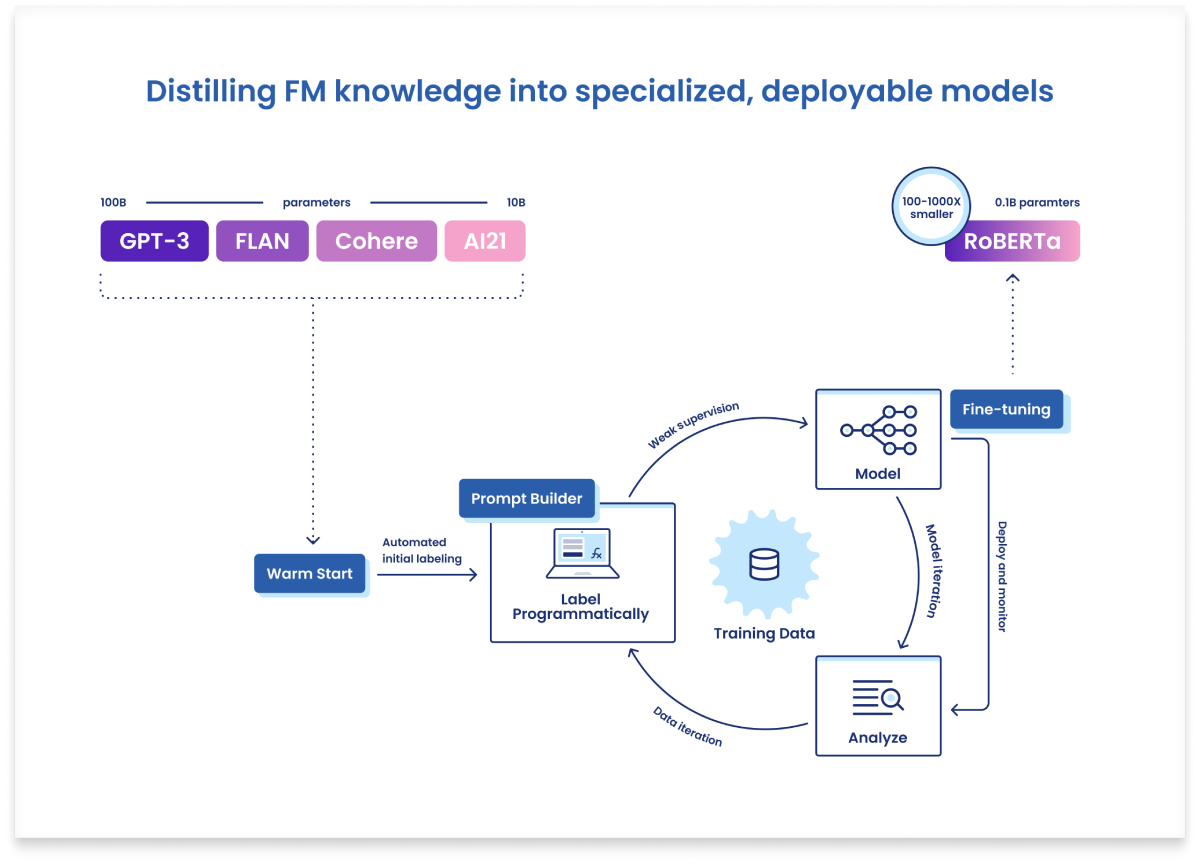
First, guys from Snorkel proposed an approach to distilling knowledge from so-called foundational models into a smaller fine-tuned model. Resembles increasing the abstraction levels, doesn't it?
Elegantly modelling the Elegans
Another thing that caught my mind recently was a news article on liquid neural networks. The authors propose a somewhat new approach, trying to model the neuronal model and, it seems, succeeding:
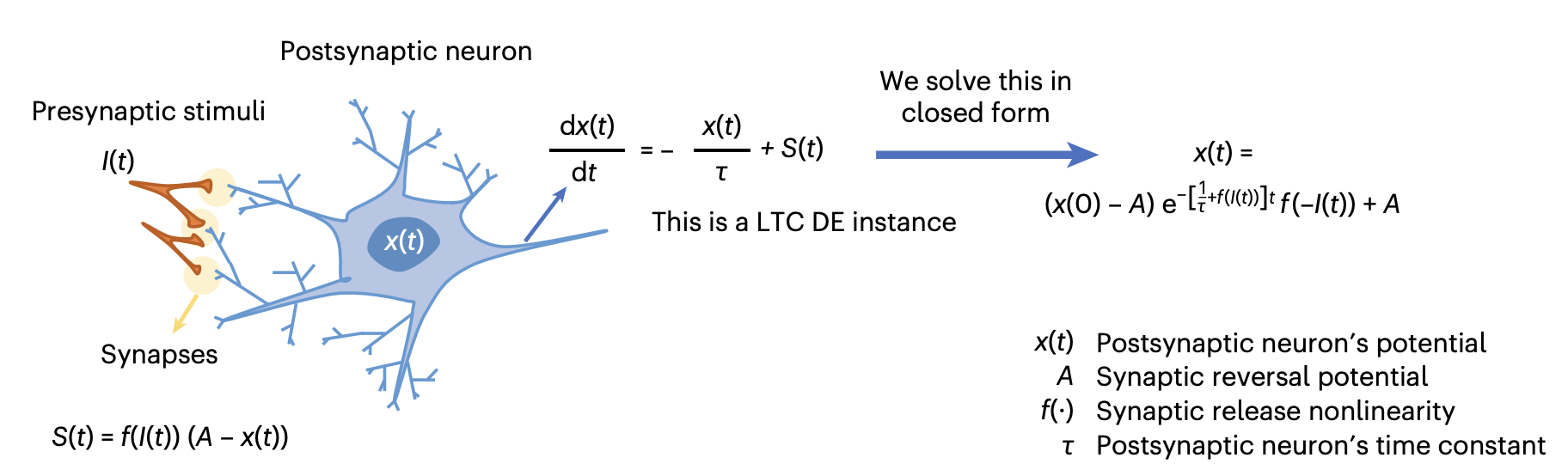
They're claiming both higher accuracy, and lower resource requirements:
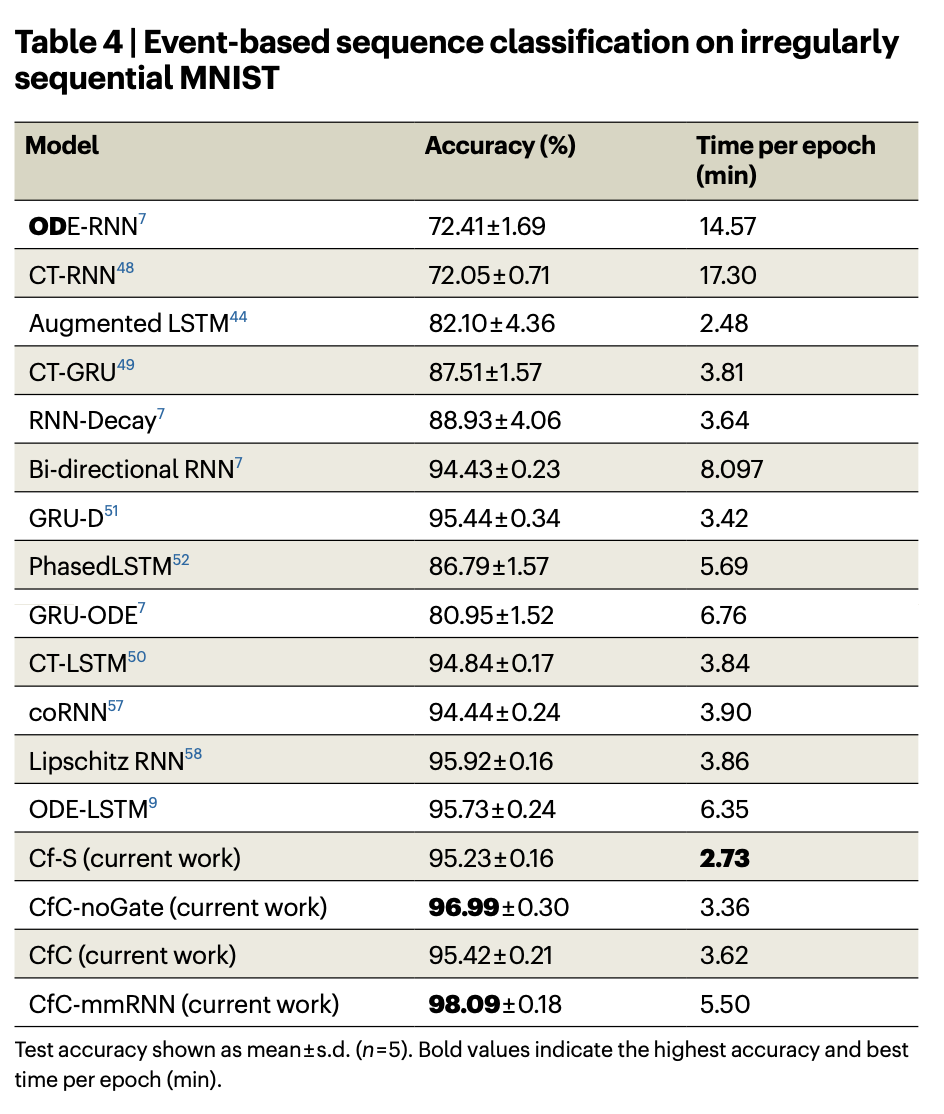
and (!) achieving high adaptability with a fraction of complexity - say, a liquid network consisting of 19 neurons and 253 synapses could drive a car.
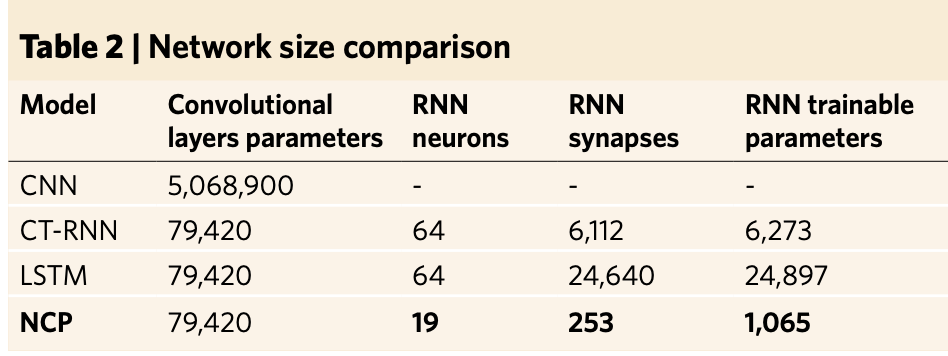
Their findings on improving current research align well with my ramblings on pruning and connecting neurons:
The next step, Lechner said, “is to figure out how many, or how few, neurons we need to perform a given task.” The group also wants to devise an optimal way of connecting neurons. Currently, every neuron links to every other neuron, but that’s not how it works in C. elegans, where synaptic connections are more selective. Through further studies of the roundworm’s wiring system, they hope to determine which neurons in their system should be coupled together.
Distribute every neuron!
Some of the models can be run distributed, e.g. LLMs with petals package:
Not a solution, but still a viable first step to edge/hivemind?
While our platform focuses on BLOOM now, we aim to support more foundation models in future.
Intermediate thoughts
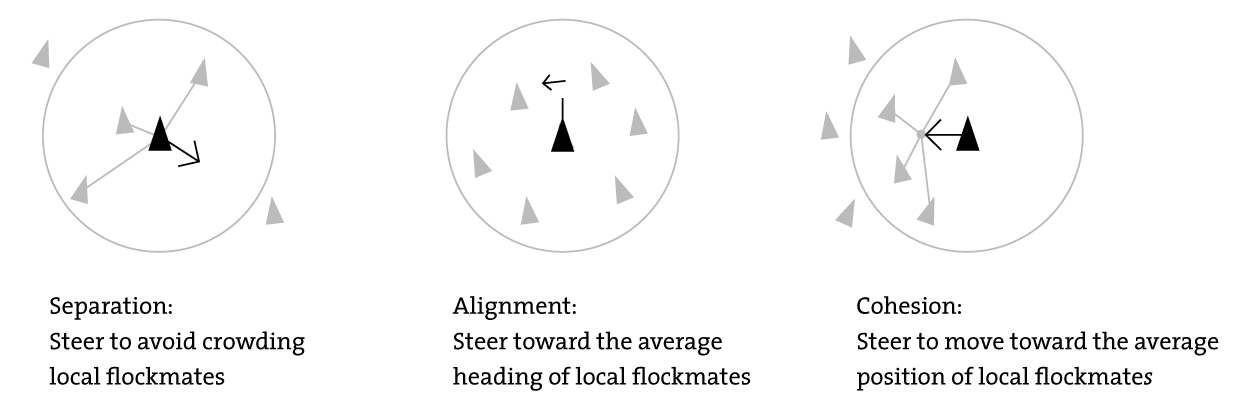
I reckon that AI systems can be viewed as a subset of complex systems, with the propensity of becoming complex adaptive systems. CAS follow a set of rules, sometimes pretty simple - e.g. GoL and birds flocking behaviour:
Proposal
We can derive from some findings of mean-field game theory (it studies small agents in extremely large populations) and evolutionary game theory (self-explanatory) as well as evolutionary algorithms, multi-armed bandits, and in the end, we could come out with a framework akin to mechanism design-inspired, that will be useful for designing/simulating multi-agent cooperative or competitive behaviour in complex and changing systems for achieving simple, and more complex, goals (e.g. anything from an ensemble of trading robots to simulating a voting process, or a marketing simulation as well as factory robots). I.e. something that will define and guide (AI terms in brackets):
population size, its structure, and changing nature (neurons and layers, changing structure and pruning the ‘unnecessary’ ones + possibly individual 'epochs' for every agent)
optimal resource allocation (computational power directed to each neuron, or agent, as per its exploration/exploitation and fitness success; defining sub-populations for sub-goals and allocating resources to those)
incentives and subsequent feedback loops, positive and negative (reward functions)
agent interactions, their types, and parameters (synapses and neuron connections + activation/inhibition functions)
the environment in accordance with the final objective, its changing parameters (the feedback/supervision the agents are receiving + their ability to act semi-autonomously + second-order environment changes from actor actions + environment spontaneous mutation rate ⇢ defining sub-goals to achieve the final goal)
understand the causal relationships (causal, not correlative-generative, learning)
I agree that this steers closer and closer to emulating the brain(s) of semi-sentient beings in a cooperative-competitive landscape - or, basically, the world? But let’s try distilling that, tackling the advantages and disadvantages of systems of different natures:
we shouldn’t repeat the errors found in current biological brains, e.g. self-reinforcing positive loops such as sugar;
we should, in the case of designing digital systems, take advantage of their nigh-absolute memory and choose the learning rate/everything;
in the case of designing mainly but not only social systems, but we must also avoid possible agent attack vectors and, again, self-reinforcing for objective optimization, i.e. Goodhart’s law;
the approach should be modular, having a set of models for each step/area aforementioned;
preferably, the simpler/less computationally expensive, the better - if we plan on implementing that in a decentralized way (say, on a decentralized machine like the EVM), that may hold merit;
also, there ideally could/should be ways of achieving approximate solutions with fewer resources, incl. time, spent. I.e. a 70-80% confident result with 20% of resources spent - a Pareto kind of probing and testing.
Welcome to YAWN/Boi Diaries❣️ You can find the other blogs I try to cross-post to: